本地部署适合以下情况:
- 电脑配置较高,有独立显卡。
- 有私密的数据需要处理,担心泄密。
- 需要和本地工作流结合,处理高频任务或复杂任务。
- 日常使用量大,调用API需要收费,本地部署能省钱。
- 想要在开源模型基础上,做个性化的定制版本。
第一步:安装olama本地部署
安装ollama(理解为:一个装AI的盒子)
1.首先在浏览器搜索ollama,会出现ollama官网,点击进入。
2.进入官网后,点击中间的Download。
3.根据自己的电脑类型,选择不同版本。
4.下载后,点击安装。如果桌面出现了olama图标,说明软件安装成功。图标就是下图的羊驼。

特别说明:最好安装在C盘,安装在其它盘,需要重新配置环境变量。
第二步,选择要安装的模型5,点击红框中的"Models"按钮
7.点击选择deepseek-r1
8.选择不同参数的模型这里的数字越大,参数越多,性能越强,1.5b代表模型具备15亿参数。我的电脑16G显存运行14b参数模型时,需要大约11.5G显存。如果是1.5b版本,2G以下的显存就可以运行,甚至不需要独立显卡核显就可以。如果是32b参数的,就需要32G显存!曰己的电脑性能选择。
参考值如下:
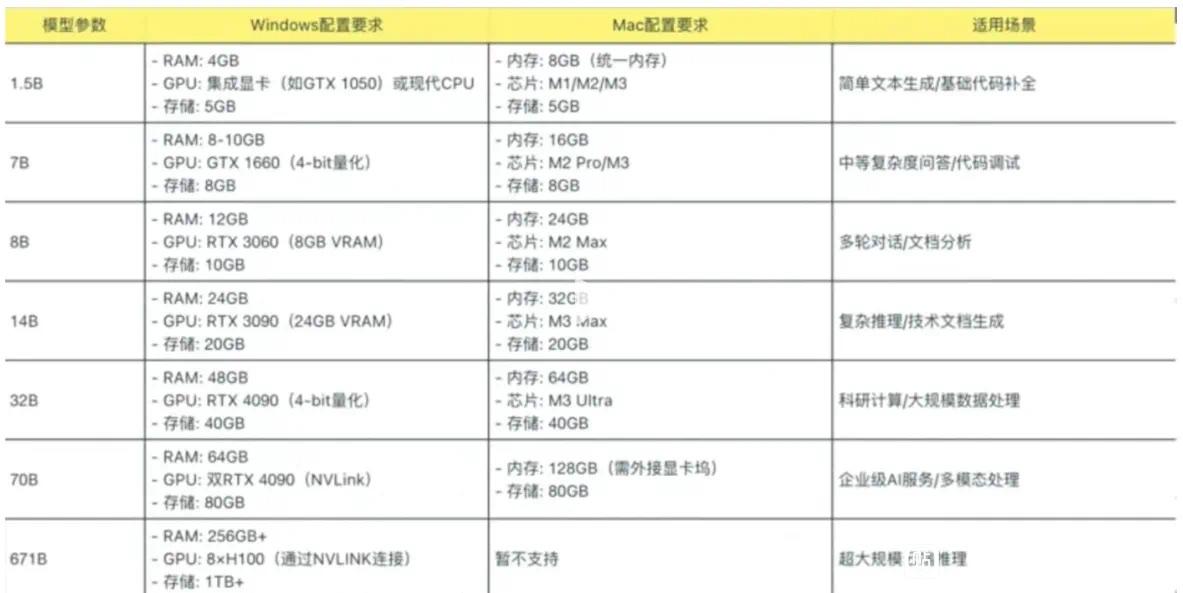
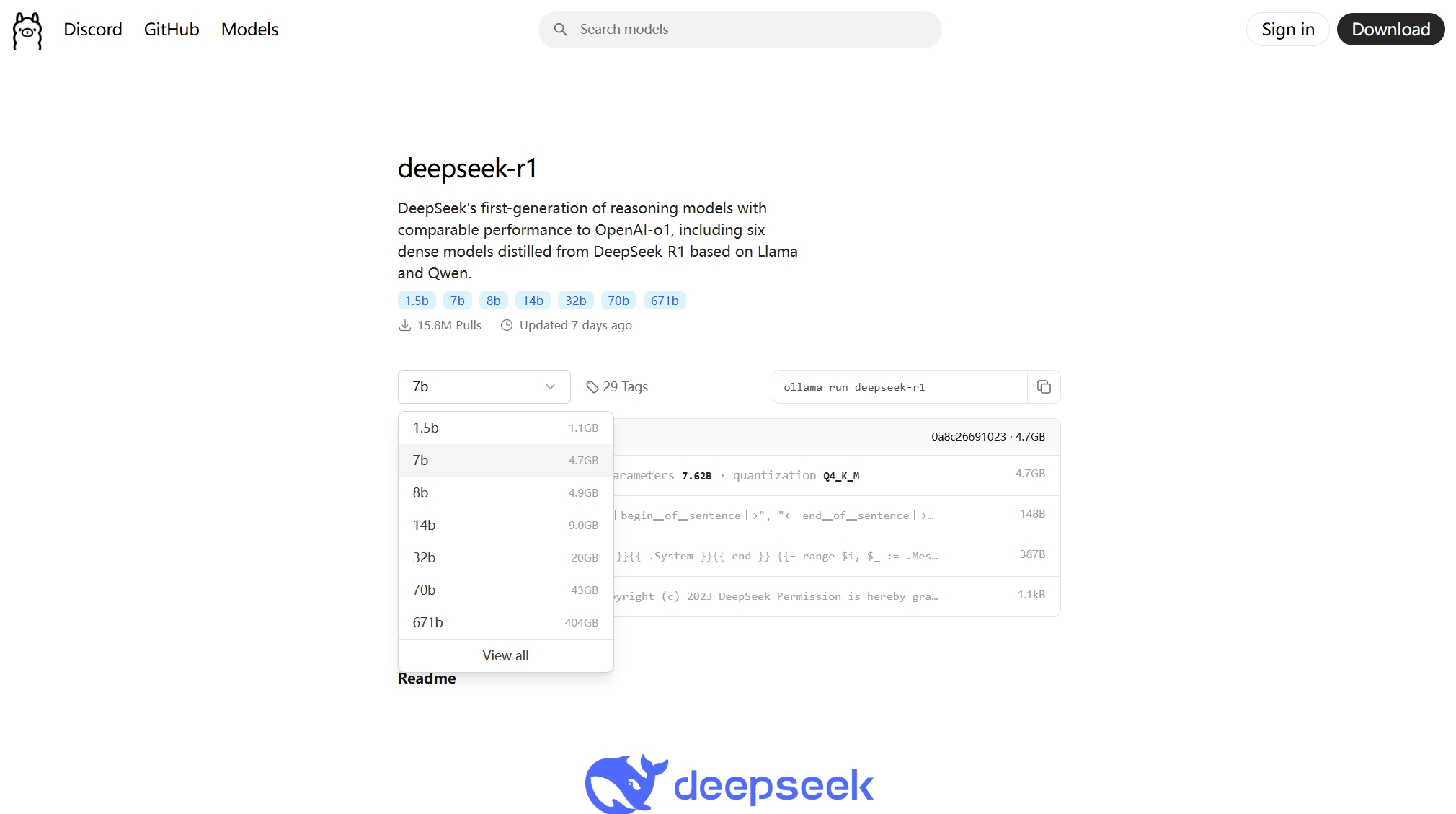
下面选择1.5b参数做示范。
9.复制命令选择1.5b多日主中的命令"ollama run deepseek-r1:1.5b”.
第三步,安装模型10.打开命令行同时按下键盘上的Win和R键,弹出如下窗口。
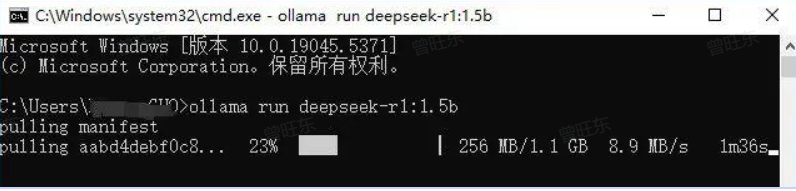
11.输入下载命令在打开的命令行里,输入上面复制的命令"ollama run deepseek-r1:1.5b"。

点击键盘上的“Enter“键,模型会自动下载。
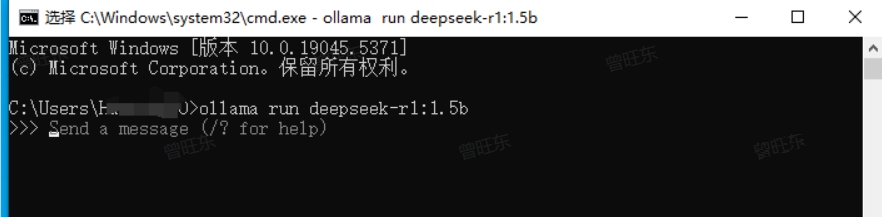
12.与模型对话下载成功后,就可以与模型对话啦。
此时大模型安装在你的电脑上,就算断网也可以继续用,也不用担心数据泄露。第四步,后续运行模型这里还有一个问题,当你关闭电脑后,下次再打开ollama。会发现点击olama的图标,电脑没反应。因为你点击图标,只是启动了olama,想要和大模型聊天,还是需要打开命令行。13.继续通过命令行和大模型聊天同时按下键盘上的Win和R键,在弹出的窗口里输入cmd,点击确定打开命令行。在命令行界面,输入刚刚的命令"ollama run deepseek-r1:1.5b”。因为你之前已经下载过,这次无需下载,可以直接和模型聊天。
数据投喂训练 AI
-
下载 nomic-embed-text:在终端输入
ollama pull nomic-embed-text回车下载 nomic-embed-text 嵌入式模型。 -
安装 AnythingLLM:进入官网,选择对应系统版本的安装包进行下载。选择 “所有用户” 点击下一步,可修改安装位置,点击完成。软件打开后,点击 “Get started”,点击箭头进行下一步,输入工作区名称,点击下一步箭头。点击 “设置”,可设置模型、界面显示语言等,若软件显示英文,可在 Customization 外观定制里面选择中文。
-
AnythingLLM 设置
-
LLM 首选项界面:提供商选择 Ollama,Ollama Model 选择前面下载的 DeepSeek - R1 系列模型 1.5b-671b,点击 Save changes。
-
Embedder 首选项界面:嵌入引擎提供商选择 Ollama,Ollama Embedding Mode 选择 “nomic-embed-text”,点击保存更改。
-
工作区设置:点击 “工作区设置”,点击聊天设置,工作区 LLM 提供者选择 “Ollama”,工作区聊天模型选择 “deepseek-r1” 模型,点击 “Update workspace agent”。代理配置界面,工作区代理 LLM 提供商选择 “Ollama”,工作区代理模型选择 “deepseek-r1”,点击 “Update workspace agent”。
-
-
数据投喂:在工作区界面,点击 “上传”,点击 upload 选择需要上传的文件,勾选上传的文件,点击 “Move to Workspace”,点击 “Save and Embed”。



















