在人工智能快速发展的今天,多模态模型因其强大的信息整合能力而备受关注。R1-Onevision是一款开源的多模态大语言模型,专注于复杂视觉推理任务。它基于Qwen2.5-VL微调而成,通过整合视觉和文本数据,能够精准地进行多模态信息解释。在数学、科学、深度图像理解和逻辑推理等领域,R1-Onevision的表现尤为出色,甚至超越了Qwen2.5-VL-7B和GPT-4V等先进模型。
R1-Onevision的核心优势在于其同时处理图像和文本输入的能力,通过先进的embedding技术实现高效的信息提取与关联。其训练数据集涵盖了自然场景、科学、数学问题、OCR内容和复杂图表等多个领域,进一步提升了模型的推理能力。
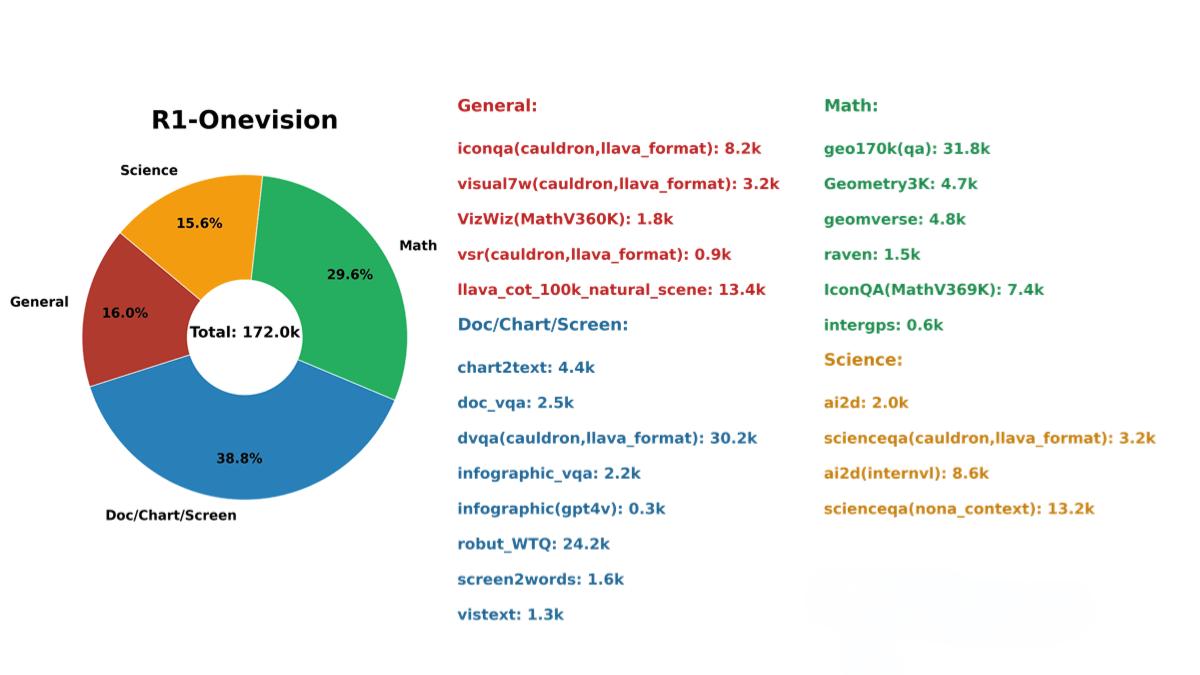
R1-Onevision的主要功能
-
多模态融合与推理 R1-Onevision能够同时处理图像和文本输入,通过先进的embedding技术实现视觉与语言信息的高效整合。在数学、科学、深度图像理解和逻辑推理等领域,它表现尤为出色。
-
复杂推理能力 通过形式语言和规则强化学习,R1-Onevision具备深度推理能力,能够在高难度推理任务中提供精准答案。
-
多样化应用场景 R1-Onevision的应用场景广泛,包括科学研究、教育工具、图像理解以及工业领域。它可以帮助科学家分析复杂数据集,为学生提供精准指导,或用于医疗影像分析和自动驾驶等场景。
-
基准测试与数据集支持 R1-Onevision团队开发了R1-Onevision-Bench基准测试,涵盖逻辑推理、数学、物理和化学问题,用于评估模型在不同领域的推理能力。
-
自监督学习与优化 R1-Onevision通过群组相对策略优化(GRPO)进行强化学习自我探索,减少了对大量标注数据的依赖,提升了学习速度和泛化能力。
R1-Onevision的技术原理
-
形式化语言驱动的推理 R1-Onevision引入了形式化语言(Formal Language)来表达图像内容,使推理过程更加精确和可解释。这种设计提升了推理的准确性,同时使模型的推理过程更加透明,便于理解和验证。
-
基于规则的强化学习 在训练过程中,R1-Onevision采用了基于规则的强化学习(Rule-Based Reinforcement Learning, RL),通过明确的逻辑约束和结构化输出,确保模型在推理过程中遵循逻辑推导的原则。
-
精心设计的数据集 R1-Onevision的数据集通过密集标注技术捕捉图像的细节信息,结合语言模型的推理能力生成更具逻辑性的文本描述。
-
强化学习优化 R1-Onevision借鉴了DeepSeek的GRPO(Generative Reward Processing Optimization)强化学习技术,通过自监督学习和优化,减少了对大量标注数据的依赖。
-
模型架构与训练 R1-Onevision基于Qwen2.5-VL微调而成,采用全模型监督微调(Full Model SFT)方法。在训练过程中,使用了512分辨率的图像输入以节省GPU内存。通过优化学习率和梯度累积等技术,进一步提升了训练效率。
R1-Onevision的项目地址
-
HuggingFace模型库:https://huggingface.co/Fancy-MLLM/R1-Onevision-7B
R1-Onevision的应用场景
-
科学研究与数据分析 R1-Onevision在数学、物理和化学等领域的复杂推理任务中表现出色,能够帮助科学家分析复杂的数据集,解决高难度的逻辑问题。
-
教育工具 R1-Onevision可以作为教育辅助工具,为学生提供精准的解答和指导。它能够解析复杂的科学问题或数学题目,以清晰的逻辑推理过程帮助学生理解。
-
图像理解与分析 R1-Onevision能够对自然场景、复杂图表和图像进行深度分析。例如,在街景照片中识别潜在的危险物体,为视障人士提供导航支持。
-
医疗影像分析 在医疗领域,R1-Onevision可以用于分析医学影像,辅助医生进行诊断。其多模态推理能力能够结合图像与文本信息,提供更准确的分析结果。
-
自动驾驶与智能交通 R1-Onevision可以应用于自动驾驶场景,帮助车辆更好地理解复杂的交通环境,识别潜在危险并做出合理的决策。
结语
R1-Onevision作为一款开源的多模态视觉推理模型,凭借其强大的技术优势和广泛的应用场景,正在成为AI领域的重要工具。无论是科学研究、教育辅助,还是医疗和自动驾驶,R1-Onevision都展现出了巨大的潜力。如果您对多模态模型感兴趣,不妨访问其Github仓库或HuggingFace模型库,亲自体验这一引领未来的AI工具。



















