一、MME-CoT 是什么?
MME-CoT(Multimodal Multifaceted Evaluation for Chain-of-Thought)是由香港中文大学(深圳)、香港中文大学、字节跳动、南京大学、上海人工智能实验室、宾夕法尼亚大学和清华大学等顶尖机构联合推出的多模态模型链式思维推理能力评估框架。
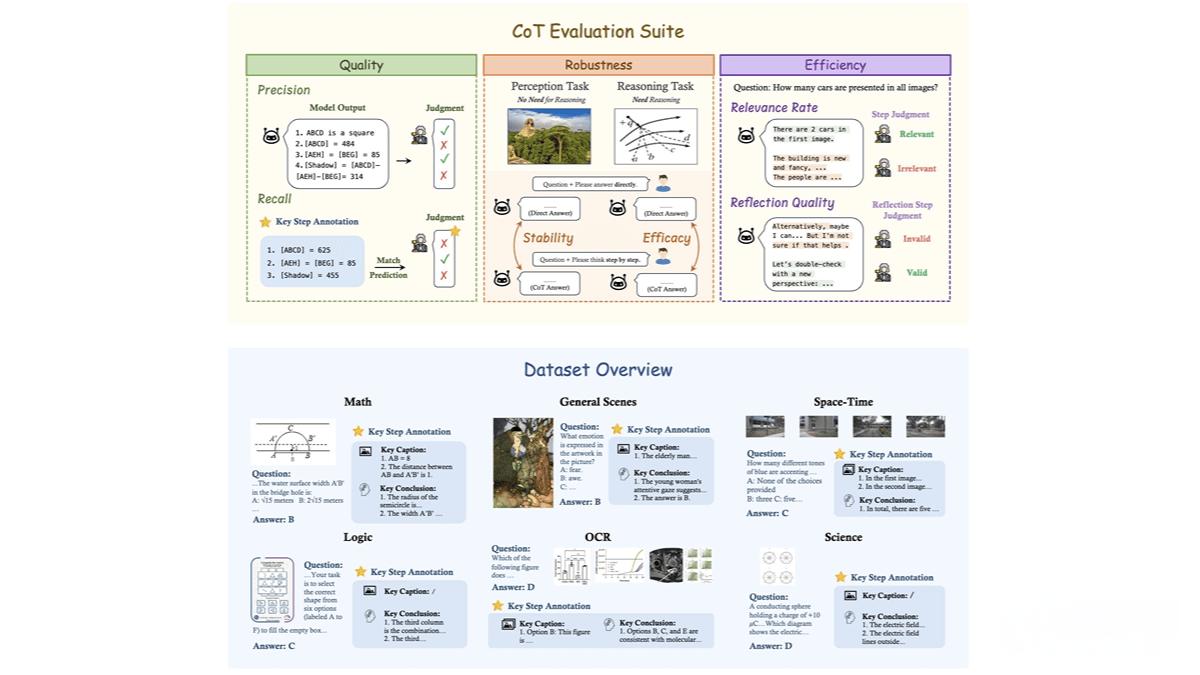
这一框架旨在全面评估大型多模态模型(LMMs)在复杂推理任务中的表现,涵盖数学、科学、OCR、逻辑、时空和一般场景等六个核心领域。通过 1,130 个精心设计的问题,MME-CoT 为研究人员提供了一个标准化的基准工具,用于测试模型的推理质量、鲁棒性和效率。
二、MME-CoT 的核心功能
-
多领域推理能力评估 MME-CoT 覆盖了六个主要领域,包括数学、科学、OCR、逻辑、时空和一般场景,全面测试模型在不同场景下的推理能力。
-
细粒度推理质量评估 每个问题都标注了关键推理步骤和参考图像描述,通过召回率(Recall)和精确率(Precision)评估推理步骤的逻辑合理性和准确性。
-
模型推理问题揭示 MME-CoT 的实验结果揭示了当前多模态模型在 CoT 推理中存在的问题,例如反思机制的低效性和对感知任务的干扰。
-
为模型优化提供参考 通过细粒度的评估指标,MME-CoT 为多模态模型的设计和优化提供了重要参考,帮助研究人员改进模型的推理能力。
三、MME-CoT 的技术原理
-
多模态数据集构建 MME-CoT 构建了一个高质量的多模态数据集,包含 1,130 个问题,覆盖六个领域和 17 个子类别。每个问题都标注了关键推理步骤和参考图像描述,用于评估模型的推理过程。
-
细粒度评估指标
-
推理质量:基于召回率和精确率,评估推理步骤的逻辑合理性和准确性。
-
推理鲁棒性:通过稳定性(Stability)和效能(Efficacy),评估 CoT 对感知任务和推理任务的影响。
-
推理效率:基于相关性比例(Relevance Rate)和反思质量(Reflection Quality),评估推理步骤的相关性和反思的有效性。
-
-
推理步骤解析与评估 使用 GPT-4 等模型将模型输出解析为逻辑推理、图像描述和背景信息等步骤,逐一对步骤进行评估,确保评估的全面性和准确性。
四、MME-CoT 的应用场景
-
模型评估与比较 MME-CoT 作为标准化基准框架,可用于评估和比较不同多模态模型在推理质量、鲁棒性和效率方面的表现。
-
模型优化 基于细粒度评估指标,MME-CoT 揭示模型在推理过程中的问题,为优化模型提供明确的方向。
-
多模态研究 为多模态推理研究提供工具,帮助研究人员探索新的模型架构和训练方法。
-
教育与培训 MME-CoT 可用于教育领域,帮助学生和研究人员理解多模态模型的推理逻辑。
-
行业应用 在智能教育、自动驾驶、医疗影像等领域,MME-CoT 可用于评估和改进模型的实际应用表现。
五、MME-CoT 的项目资源
-
GitHub 仓库:https://github.com/CaraJ7/MME-CoT
-
HuggingFace 模型库:https://huggingface.co/datasets/CaraJ/MME-CoT
-
arXiv 技术论文:https://arxiv.org/pdf/2502.09621
六、结语
MME-CoT 的推出为多模态模型的研究和优化提供了重要工具,其全面的评估框架和细粒度的指标体系为 AI 领域的发展注入了新的活力。无论是研究人员、开发者还是行业应用者,都可以通过 MME-CoT 框架提升对多模态模型的理解和应用能力,推动 AI 技术的进一步发展。



















