在生物技术领域,DNA序列的设计和优化一直是研究的核心挑战。阿里云飞天实验室AI for Science团队推出的GENERator,作为一款专注于DNA序列生成的生成式基因组基础模型,正在重新定义这一领域的研究方式。本文将深入探讨GENERator的技术原理、功能优势及其在多个应用场景中的潜力。
什么是GENERator?
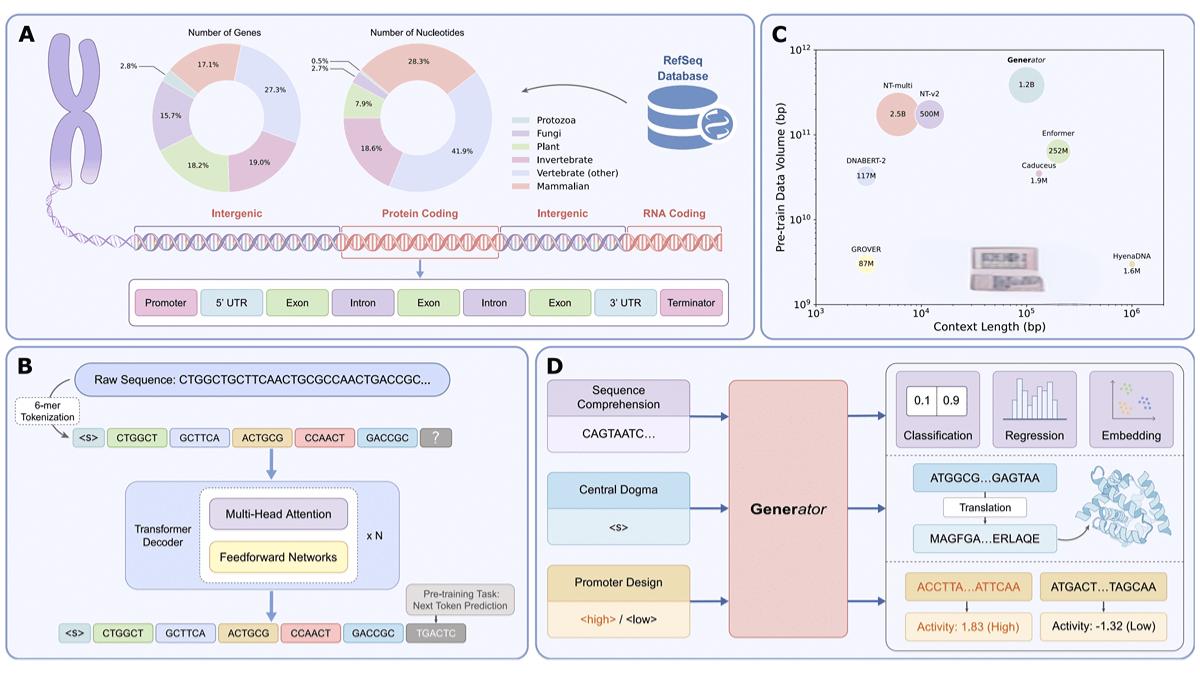
GENERator是一款由阿里云飞天实验室AI for Science团队开发的生成式DNA大模型,专注于DNA序列的设计和生成。基于Transformer解码器架构,模型具有98k碱基对的上下文长度和12亿参数,训练数据涵盖3860亿bp的真核生物DNA。其在多个基准测试中表现出色,能够生成与天然蛋白质家族结构相似的DNA序列,并在启动子设计等任务中展现出优化潜力。
GENERator的核心功能
-
DNA序列生成 GENERator能够生成具有生物学意义的DNA序列,编码与已知蛋白质家族结构相似的蛋白质。例如,它成功生成了组蛋白和细胞色素P450家族的全新变体,为蛋白质工程提供了新的可能性。
-
启动子设计 通过微调,GENERator可以设计具有特定活性的启动子序列,用于调控基因表达。实验表明,生成的启动子序列在活性上与天然样本有显著差异,展现出强大的基因表达调控潜力。
-
基因组分析与注释 在基因分类和分类群分类任务中,GENERator表现出色,能够高效识别基因位置、预测基因功能并注释基因结构。
-
序列优化 GENERator在序列优化方面展现出显著潜力,通过指令生成具有特定活性的DNA序列,为合成生物学和基因工程提供了新的工具。
技术原理:驱动GENERator的核心
-
Transformer解码器架构 GENERator采用Transformer解码器架构,通过多头自注意力机制和前馈神经网络实现高效的序列建模。解码器能够处理长序列,在生成过程中避免看到未来信息,保证生成的序列符合生物学逻辑。
-
超长上下文建模 模型具有98k碱基对的上下文长度,能够处理复杂的基因结构,在生成长序列时保持连贯性和生物学意义。
-
6-mer分词器 GENERator使用6-mer分词器,将DNA序列分割为长度为6的核苷酸片段。在生成任务中表现优于单核苷酸分词器和BPE分词器,平衡了序列分辨率和上下文覆盖。
-
预训练策略 模型在大规模数据上进行预训练,数据集包含3860亿bp的真核生物DNA。预训练任务采用Next Token Prediction(NTP),通过预测下一个核苷酸来学习DNA序列的语义。
-
生物学验证 模型生成的DNA序列能够编码与天然蛋白质家族结构相似的蛋白质。通过Progen2计算生成序列的困惑度(PPL)以及使用AlphaFold3预测其三维结构,验证了生成序列的生物学意义。
应用场景:从实验室到现实
-
DNA序列设计与优化 GENERator能够生成具有生物学意义的DNA序列,例如用于蛋白质家族的定制。它能够生成与天然蛋白质家族结构相似的DNA序列,如组蛋白和细胞色素P450家族的变体。
-
基因组分析与注释 在基因组学研究中,GENERator可以高效识别基因位置、预测基因功能并注释基因结构,为基因组研究提供了强大的工具。
-
合成生物学与基因工程 GENERator提供了一种新的工具,用于设计和优化基因表达调控元件(如启动子和增强子),在合成生物学和基因工程中具有重要应用价值。
-
精准医疗与药物设计 通过生成与特定疾病相关的基因序列,GENERator可以为精准医疗和药物设计提供支持,用于设计用于基因治疗的靶向序列。
-
生物技术中的序列优化 GENERator能够通过指令生成具有特定功能的DNA序列,为生物技术中的序列优化提供了新的可能性。
项目资源与技术支持
-
HuggingFace模型库:https://huggingface.co/GenerTeam
结语:AI驱动的基因组学未来
GENERator的推出标志着AI在基因组学领域的又一重要突破。凭借其强大的技术能力和广泛的应用场景,它正在为合成生物学、精准医疗和药物设计等领域带来革命性的变化。无论是研究人员还是生物技术从业者,都可以通过这一工具探索基因组学的无限可能。



















