DiffRhythm 由西北工业大学和香港中文大学(深圳)的研究团队联合开发,旨在解决现有音乐生成工具的局限性,如生成完整长歌的困难、复杂多阶段架构和慢速推理等问题。
-
它基于潜扩散模型,首次实现端到端生成包含人声和伴奏的完整歌曲,长达 4 分 45 秒,仅需 10 秒。
-
相比传统工具,DiffRhythm 采用非自回归结构,简化数据管道,提升可扩展性,适合艺术创作、教育和娱乐应用。
-
开发团队强调其简单性,旨在让用户无需复杂设置,仅需歌词和风格提示即可生成音乐。
网络搜索结果(如 DiffRhythm AI Music Generator)进一步证实其快速生成和高品质输出,受到用户好评,尤其在处理复杂歌词和多语言支持方面表现突出。
核心功能与优势
DiffRhythm 的功能设计贴合用户需求,以下为详细列表:
| 功能 | 描述 |
|---|---|
| 快速生成完整音乐 | 10 秒内生成长达 4 分 45 秒的歌曲,包括人声和伴奏,效率远超传统工具。 |
| 歌词驱动的音乐创作 | 用户输入歌词和风格提示(如“流行”“古典”),自动生成匹配的旋律和伴奏。 |
| 高质量音乐输出 | 旋律流畅,歌词清晰,适合影视配乐、短视频背景音乐等场景。 |
| 灵活的风格定制 | 支持多种风格调整,通过简单提示满足多样化创作需求。 |
| 开源与可扩展性 | 提供训练代码和预训练模型,支持用户自定义开发和二次创作。 |
| 创新的歌词对齐技术 | 通过句子级对齐机制,确保人声与旋律高度匹配,提升听觉体验。 |
这些功能使其成为专业音乐人、独立创作者和教育者的理想工具。例如,网络搜索显示用户评价其在生成英中双语歌曲时的多功能性,特别适合跨文化创作。
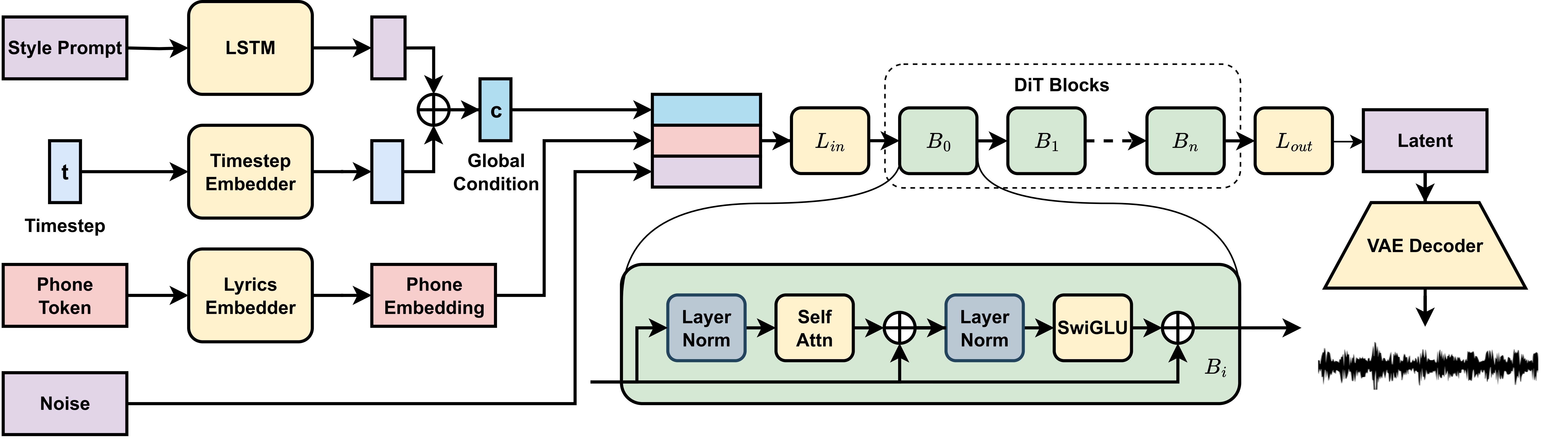
技术原理
DiffRhythm 的技术核心基于潜扩散模型,结合变分自编码器(VAE)和扩散变换器(Diffusion Transformer):
-
潜扩散模型:通过前向加噪将音乐片段逐步转为白噪声,再通过预训练神经网络反向去噪,生成符合用户需求的音乐。
-
自编码器结构:VAE 将音频信号压缩为潜在特征表示,扩散模型生成新特征,最后解码为音频输出,降低计算复杂度。
-
扩散变换器:基于变换器架构,利用交叉注意力层和门控多层感知器处理长上下文窗口,确保音乐结构连贯。
这些技术使 DiffRhythm 能在短时间内生成高质量、结构完整的长歌,网络搜索结果(如 DiffRhythm 技术论文)详细阐述其方法,强调其在音乐生成领域的创新性。
使用方法与资源
用户可以多种方式访问 DiffRhythm:
-
在线平台:通过 Hugging Face Space (DiffRhythm Space) 体验,无需本地设置,适合初学者。
-
本地运行:从 GitHub 仓库 (DiffRhythm GitHub) 下载,安装 Python 3.10 和相关依赖(如 espeak-ng),需至少 8GB VRAM。
-
输入与生成:提供 lrc 格式歌词和参考音频,指定风格提示,运行推理脚本生成歌曲。
网络搜索显示,部分第三方平台(如 DiffRhythm AI)也提供在线工具,但建议使用官方资源以确保安全性。项目资源包括:
-
官方网站 (DiffRhythm 官网)
-
Hugging Face 模型库 (Hugging Face Models)
-
技术论文 (技术论文)
应用场景与潜在影响
DiffRhythm 的应用场景涵盖多个领域:
| 场景 | 具体应用 |
|---|---|
| 音乐创作辅助 | 为音乐人提供灵感,快速生成包含人声和伴奏的歌曲框架。 |
| 影视与视频配乐 | 为影视制作、游戏开发和短视频生成匹配情绪的背景音乐,提升作品感染力。 |
| 教育与研究 | 生成教学用音乐示例,帮助学生理解不同风格和结构,适合音乐教育研究。 |
| 独立音乐人与个人创作 | 独立音乐人无需复杂设备,快速生成高质量作品,支持多语言歌词输入。 |
然而,潜在风险不容忽视:
- 版权问题:生成的音乐可能与现有作品相似,需验证原创性,避免侵权。
- 文化误用:可能不恰当地融合不同文化音乐元素,需谨慎使用。
- 有害内容风险:存在被用于生成不适当内容的可能性,开发团队建议披露 AI 参与并获取保护风格的许可。
网络搜索结果(如 DiffRhythm 风险讨论)显示,社区正在积极讨论这些伦理问题,强调负责任使用的重要性。
与其他工具的比较
与其他 AI 音乐生成工具相比,DiffRhythm 的独特之处在于其端到端生成完整长歌的能力。传统工具如 Melodist 或 MusicLM 往往仅生成孤立音轨或短段,推理速度较慢。而 DiffRhythm 的非自回归结构和潜扩散模型使其在速度和质量上领先,特别适合需要快速解决方案的用户。



















