在人工智能快速发展的今天,代码生成工具正逐渐成为开发者和编程教育者的得力助手。WarriorCoder作为微软与华南理工大学联合推出的一款代码生成大语言模型(LLM),凭借其独特的技术原理和强大的功能,迅速在AI工具领域崭露头角。本文将从多个维度全面解析WarriorCoder,帮助您了解它如何助力代码开发和教育。
什么是WarriorCoder?
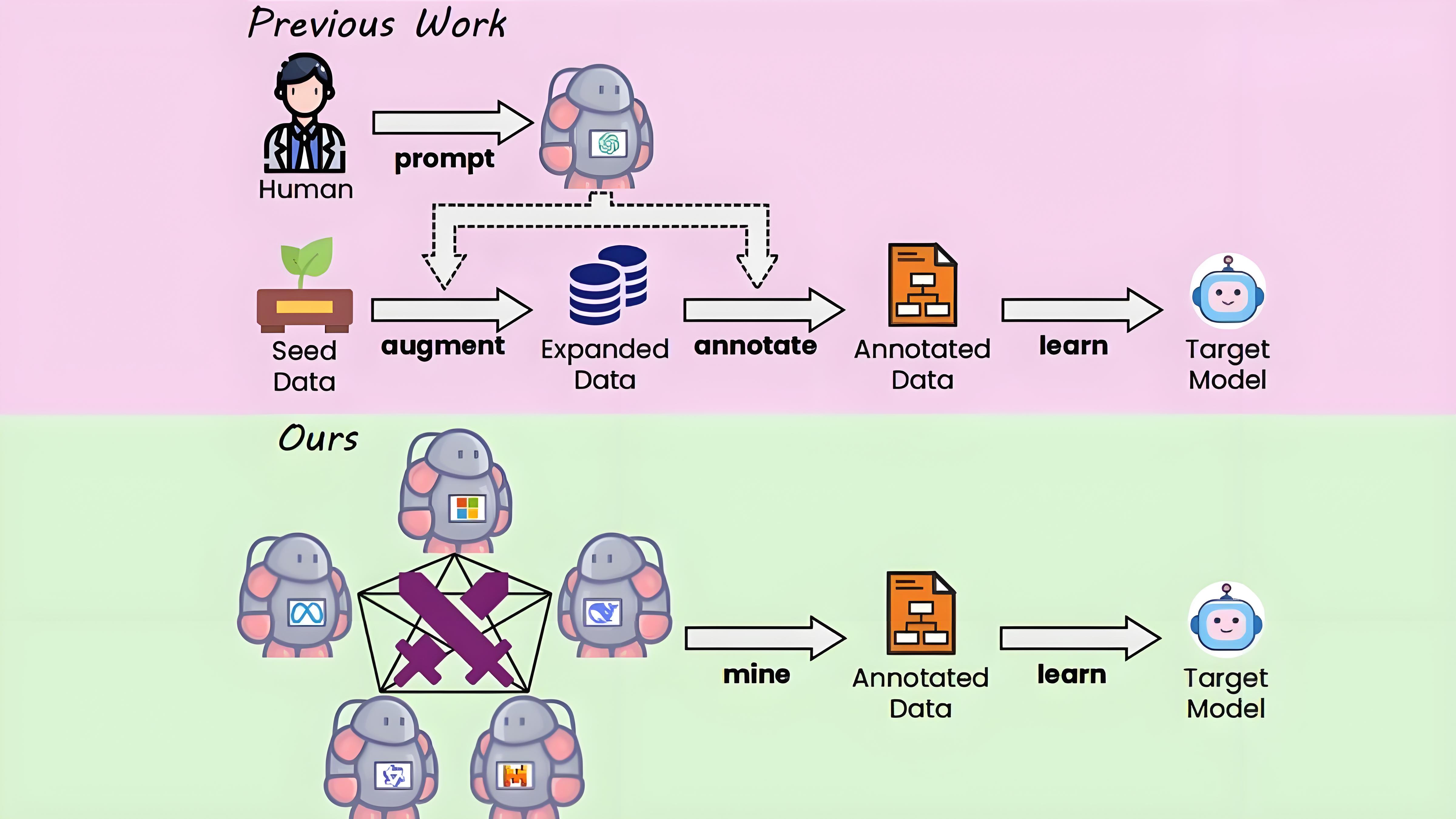
WarriorCoder是一款由华南理工大学计算机科学与工程学院与微软共同开发的代码生成大语言模型。与传统依赖专有模型或数据集的代码生成工具不同,WarriorCoder采用了一种创新的方法:通过模拟专家模型之间的对抗,生成高质量的训练数据,从而显著提升模型性能。这种方法不仅避免了数据收集过程中的人工参与和系统偏见,还整合了多个开源代码专家模型的优势。
实验结果显示,WarriorCoder在代码生成、代码推理和库使用等任务上达到了新的SOTA(state-of-the-art)性能,展现了其强大的泛化能力和数据多样性。
WarriorCoder的核心功能
WarriorCoder的功能涵盖了代码开发的多个关键环节,以下是其主要功能:
-
代码生成 根据用户提供的指令或需求,生成高质量的代码片段,帮助开发者快速实现功能。
-
代码优化 对现有代码进行优化,提高其性能和效率,使其更加简洁和高效。
-
代码调试 识别和修复代码中的错误或漏洞,减少调试时间,提升开发效率。
-
代码推理 预测代码的输出或根据输出反推输入,帮助开发者更好地理解代码逻辑。
-
库和框架的使用 生成与特定编程库(如NumPy、Pandas等)相关的代码,提升对复杂库的调用能力。
-
多语言支持 支持多种编程语言,适应不同开发场景的需求。
WarriorCoder的技术原理
WarriorCoder的技术优势在于其独特的专家对抗框架和Elo评分系统。以下是其技术原理的详细解析:
-
专家对抗框架 WarriorCoder构建了一个竞技场,让多个先进的代码专家模型(如开源LLM)相互对抗。每轮对抗中,两个模型分别扮演攻击者和防守者的角色,根据特定指令生成代码。其他模型则作为裁判,评估对抗结果。目标模型从对抗中的胜者学习,逐步整合所有专家模型的优势。
-
指令挖掘 通过基于补全的方法,WarriorCoder能够挖掘专家模型已掌握的能力,避免依赖私有数据。这种方法利用模型的生成能力,从分布中采样指令,避免模式过拟合和数据偏移。
-
难度评估与去重 对挖掘出的指令进行去重,并由裁判模型评估其难度,保留难度等级为“优秀”或“良好”的指令,确保训练数据的高质量。
-
Elo评分系统 引入Elo评分系统,结合局部对抗结果和全局表现,评估模型的综合能力。动态更新Elo评分,平衡局部偶然性和全局一致性,避免弱模型因偶然因素获胜。
-
训练与优化 使用对抗中胜者的响应作为训练数据,基于监督微调(SFT)训练目标模型。这种方法无需依赖人工标注或私有LLM,能够低成本生成多样化、高质量的训练数据。
WarriorCoder的应用场景
WarriorCoder的应用场景非常广泛,涵盖了开发、教育和跨语言转换等多个领域:
-
自动化代码生成 根据自然语言描述快速生成代码,提升开发效率。
-
代码优化与重构 提供优化建议,提升代码性能和可读性。
-
代码调试与修复 帮助定位错误并提供修复方案,减少调试时间。
-
编程教育辅助 生成示例代码和练习题,助力编程学习。
-
跨语言代码转换 支持代码从一种语言转换为另一种语言,便于技术栈迁移。
WarriorCoder的技术论文与项目地址
如果您对WarriorCoder的技术细节感兴趣,可以参考其技术论文:
-
arXiv技术论文: https://arxiv.org/pdf/2412.17395
结语
WarriorCoder作为一款由微软与华南理工大学联合开发的代码生成大语言模型,凭借其创新的技术原理和强大的功能,正在为开发者和教育者提供前所未有的便利。无论是代码生成、优化,还是编程教育,WarriorCoder都展现出了卓越的性能和广泛的应用前景。如果您是开发者或编程教育者,不妨深入了解这一AI工具,体验其带来的高效与便捷。



















