随着人工智能技术的快速发展,多模态模型(Multimodal Models)逐渐成为研究和应用的热点。Google DeepMind近期推出了一个名为WebLI-100B的超大规模视觉语言数据集,包含1000亿图像-文本对,为视觉语言模型(VLMs)的预训练提供了丰富的资源。本文将详细介绍WebLI-100B的核心特点、技术原理、应用场景及其对AI研究的深远影响。
WebLI-100B的核心特点
-
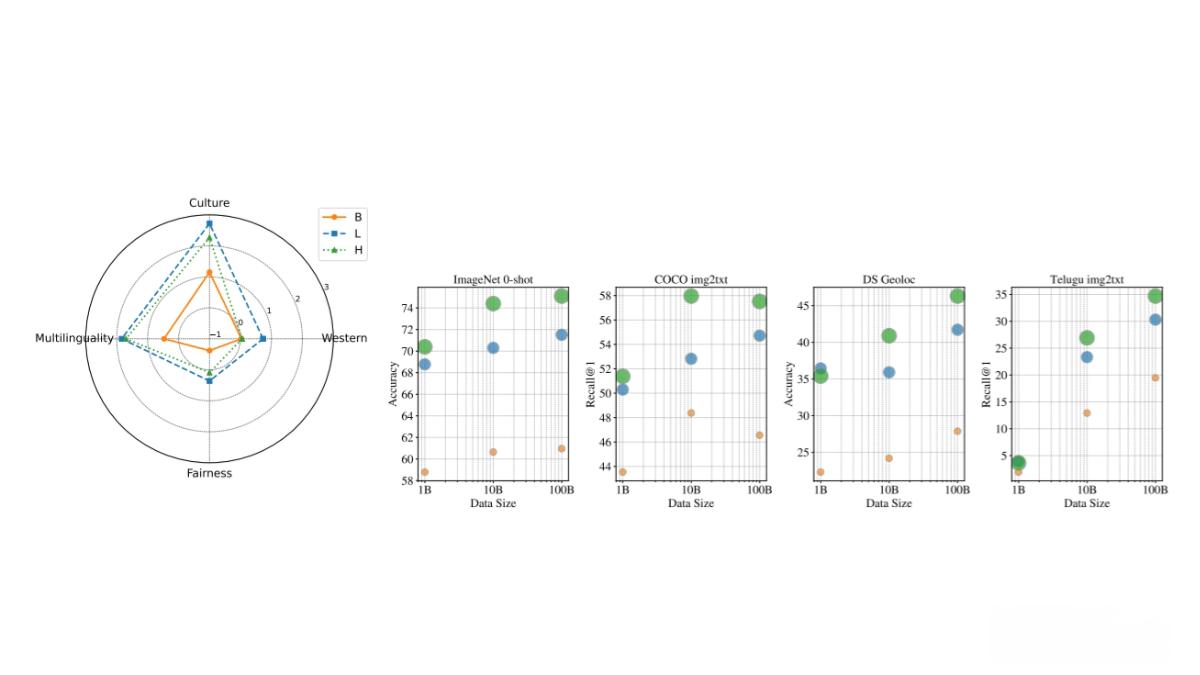
超大规模数据集 WebLI-100B是目前规模最大的视觉语言数据集之一,包含1000亿图像-文本对,是之前最大数据集的十倍。这一规模的提升显著增强了模型对长尾概念、文化多样性和多语言内容的理解能力。
-
文化多样性和多语言支持 WebLI-100B的数据来源于互联网,包含来自不同文化背景的图像和文本。通过基本数据过滤(如移除有害图像和个人身份信息),数据集保留了尽可能多的语言和文化多样性,为训练更具包容性的多模态模型提供了重要资源。
-
技术领先 WebLI-100B采用先进的数据处理技术,包括使用多语言MT5分词器对文本进行分词处理,并将图像调整为224×224像素的分辨率,以适应模型的输入要求。
WebLI-100B的技术原理
-
数据收集
-
来源:WebLI-100B的数据主要来源于互联网,通过大规模网络爬取收集图像及其对应的文本描述(如图像的alt文本或页面标题)。
-
规模:数据集包含1000亿个图像-文本对,是迄今为止最大的视觉语言数据集之一。
-
-
数据过滤
-
基本过滤:仅移除有害图像和个人身份信息(PII),以保留语言和文化多样性。
-
质量过滤(可选):研究中探讨了使用CLIP等模型进行数据过滤,但这种过滤可能会减少某些文化背景的代表性。
-
-
数据处理
-
文本处理:使用多语言MT5分词器对文本进行分词处理,确保多样性和一致性。
-
图像处理:将图像调整为224×224像素的分辨率,适应模型输入要求。
-
WebLI-100B的应用场景
-
人工智能研究者 WebLI-100B为视觉语言模型的预训练提供了丰富的数据资源,帮助研究者探索新算法,提升模型性能。
-
工程师 工程师可以利用WebLI-100B开发多语言和跨文化的应用,如图像描述生成、视觉问答和内容推荐系统。
-
内容创作者 数据集支持生成多语言的图像描述和标签,帮助内容创作者提升内容的本地化和多样性。
-
跨文化研究者 WebLI-100B为研究不同文化背景下的图像和文本提供了重要资源,支持文化差异分析。
-
教育工作者和学生 作为教学和研究资源,WebLI-100B可以帮助教育工作者和学生学习多模态数据处理和分析。
WebLI-100B的项目地址
-
arXiv技术论文:https://arxiv.org/pdf/2502.07617
结语
WebLI-100B的推出标志着视觉语言模型研究进入了一个新的阶段。其超大规模、文化多样性和技术领先性为多模态AI的发展提供了重要支持。无论是研究者、工程师还是内容创作者,都可以从中受益,推动AI技术的进一步突破。



















