在数字化转型的浪潮中,3D资产的生成与编辑已成为各个行业的重要需求。从游戏开发到影视制作,从虚拟现实到室内设计,高质量的3D模型正在改变我们的生活方式。然而,传统的3D建模过程往往耗时耗力,且难以实现多视图一致性和高分辨率纹理生成。
华为慕尼黑研究中心推出的ConsistentDreamer技术,正是为了解决这些痛点而诞生。它通过单张图像即可生成视图一致的3D网格,为3D资产生成开辟了全新的可能性。本文将带您深入了解这一革新性技术的核心优势及其应用场景。
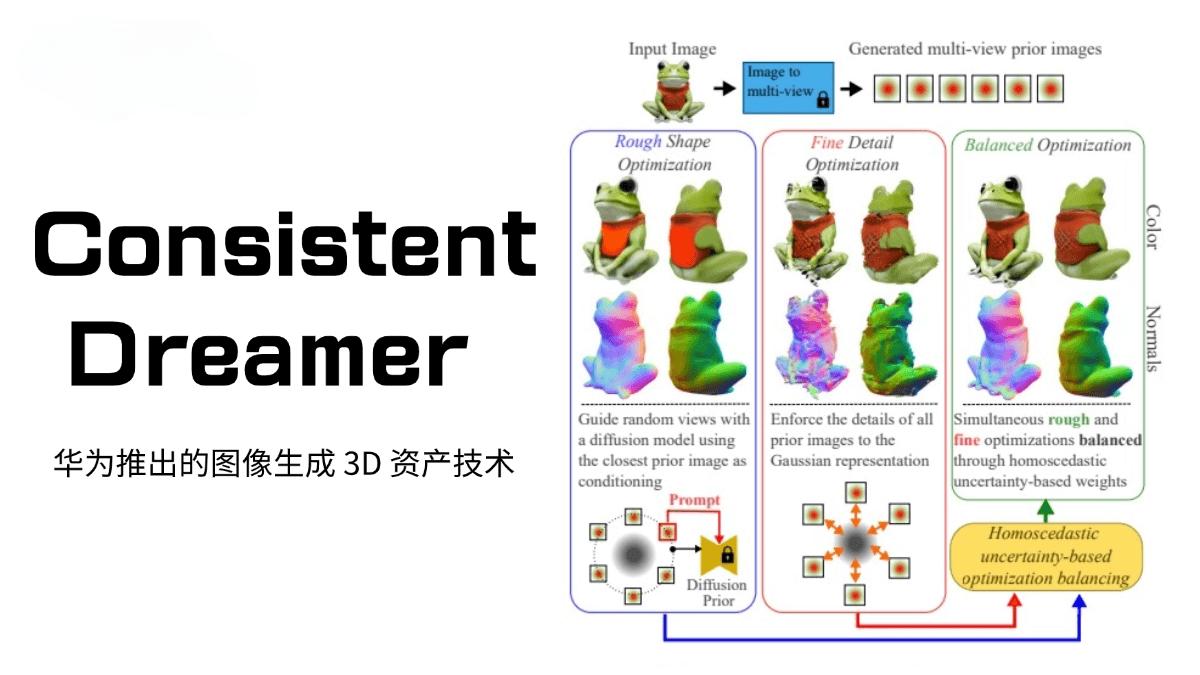
什么是ConsistentDreamer?
ConsistentDreamer是一项由华为慕尼黑研究中心开发的新型图像到3D资产生成技术。它通过单张图像输入,结合多视图先验图像引导的高斯优化,生成高质量的3D网格模型。这一技术的核心在于解决传统方法在多视图一致性和复杂场景处理上的不足。
与传统的2D扩散模型不同,ConsistentDreamer通过引入3D一致的结构化噪声和自监督一致性训练,确保在不同视图之间保持高度一致的编辑结果。此外,它还支持高分辨率纹理生成、复杂图案编辑以及指令引导的场景编辑,为3D建模领域带来了前所未有的灵活性和效率。
ConsistentDreamer的核心功能
-
3D一致性增强 通过引入3D一致的结构化噪声和自监督一致性训练,ConsistentDreamer能够在不同视图之间保持高度一致的编辑结果,解决了传统2D扩散模型在多视图生成中的不一致性问题。
-
高分辨率纹理生成 该技术能够生成具有精细纹理和高清晰度的编辑结果,尤其在复杂场景(如ScanNet++的大规模室内场景)中表现出色。
-
复杂图案编辑能力 ConsistentDreamer是首个能够成功编辑复杂图案(如格子或方格图案)的方法,为设计师和开发者提供了更大的创作自由。
-
多视图上下文输入 通过将周围视图作为输入,ConsistentDreamer为2D扩散模型提供了丰富的3D上下文信息,增强了模型的3D感知能力。
-
并行化编辑流程 采用多GPU并行处理,通过分离NeRF拟合和扩散模型生成,ConsistentDreamer实现了高效的场景编辑。
-
指令引导的场景编辑 支持根据自然语言指令对3D场景进行编辑,生成与指令高度一致的高质量结果。
技术原理深度解析
-
多视图先验图像引导 ConsistentDreamer首先基于多视图生成模型从单张输入图像生成一组固定视角的多视图先验图像。这些图像作为优化过程中的参考,为3D模型的生成提供了丰富的上下文信息。
-
分数蒸馏采样(SDS) 通过分数蒸馏采样(SDS)损失优化3D模型的粗略形状。具体来说,基于预训练的扩散模型(如Zero-1-to-3)生成随机视图,通过选择与目标视图最接近的先验图像作为条件,确保视图之间的一致性。
-
动态任务权重平衡 为了平衡粗略形状优化和精细细节优化,ConsistentDreamer引入了基于同方差不确定性的动态任务权重。在每次迭代中自动更新,确保优化过程的稳定性和效率。
-
不透明度、深度失真和法线对齐损失 为了提高网格提取的质量,ConsistentDreamer引入了不透明度损失、深度失真损失和法线对齐损失。这些损失函数帮助细化表面,确保生成的3D网格具有清晰的表面和高质量的纹理。
-
多视图上下文输入与一致性训练 ConsistentDreamer将周围视图作为输入,为扩散模型提供丰富的3D上下文信息,通过自监督一致性训练进一步强化3D感知能力。
应用场景
-
复杂场景的高保真编辑 ConsistentDreamer适用于复杂的大规模室内场景(如ScanNet++数据集中的场景),能生成具有精细纹理和高清晰度的编辑结果。
-
多样化风格转换 支持多种风格转换任务,例如将场景转换为特定的艺术风格(如梵高或蒙克风格),同时保留原始场景的细节和纹理。
-
物体特定编辑 ConsistentDreamer可以对场景中的特定物体进行编辑,例如改变人物的表情或物体的颜色。
-
跨视图和跨批次一致性 通过引入结构化噪声和自监督一致性训练,ConsistentDreamer能够在不同视图和不同批次的生成过程中保持一致性。
项目地址
如果您对ConsistentDreamer的技术细节感兴趣,可以访问其arXiv技术论文: https://arxiv.org/pdf/2502.09278
结语
华为的ConsistentDreamer技术无疑为3D资产生成领域注入了新的活力。通过单张图像生成高质量的3D模型,ConsistentDreamer不仅提升了建模效率,还为设计师和开发者提供了更大的创作自由。无论是游戏开发、影视制作,还是虚拟现实和室内设计,这一技术都将发挥重要作用。
如果您正在寻找一款高效、灵活的3D生成工具,不妨深入了解ConsistentDreamer,感受其带来的革新性体验。



















