在人工智能领域,注意力机制一直是大型语言模型(LLMs)的核心技术之一。然而,随着模型规模的不断扩大和应用场景的日益复杂,传统的注意力机制在处理长上下文任务时逐渐暴露出计算效率低、资源消耗大的问题。为了突破这一瓶颈,Moonshot AI 推出了 MoBA(Mixture of Block Attention),一种全新的注意力机制,旨在提高长文本处理的效率,同时保持与全注意力机制相当的性能。
本文将详细介绍 MoBA 的核心功能、技术原理、应用场景以及其在 AI 领域的潜力,帮助您全面了解这一创新技术。
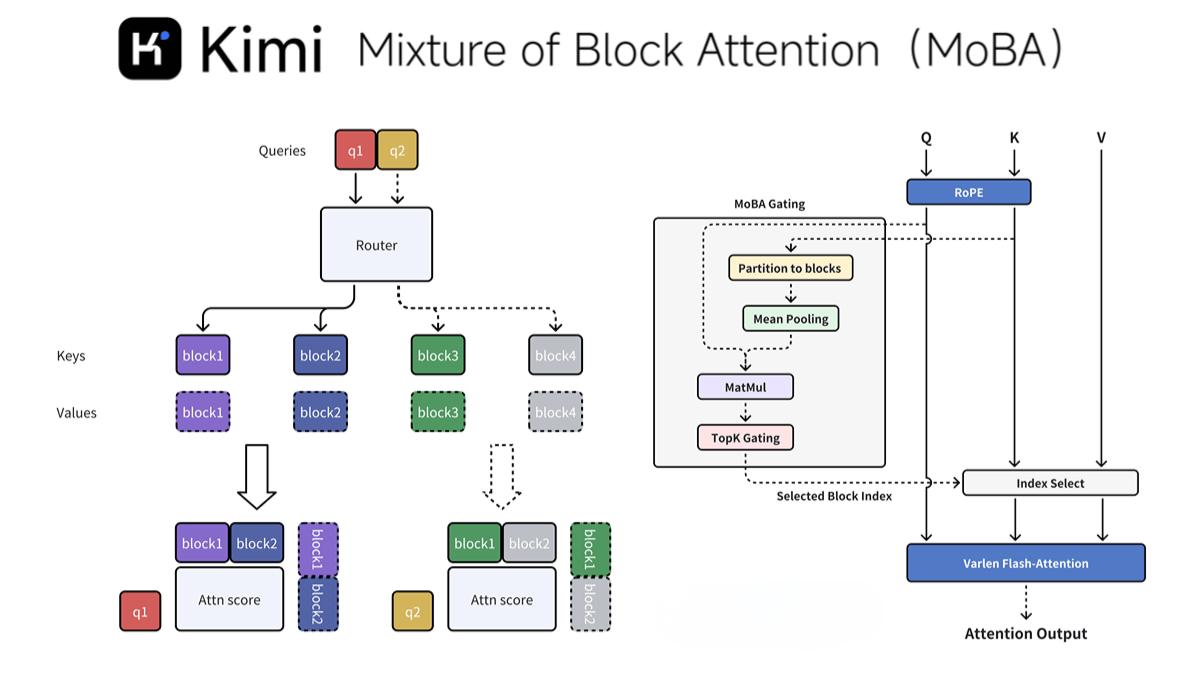
MoBA 是什么?
MoBA(Mixture of Block Attention)是一种由 Moonshot AI 提出的新型注意力机制,专为提高大型语言模型处理长上下文任务的效率而设计。通过将上下文划分为多个块(block),并引入无参数的 top-k 门控机制,MoBA 允许每个查询 token 动态选择最相关的键值(KV)块进行注意力计算,从而显著降低了计算复杂度。
MoBA 的核心优势在于其灵活性和高效性:
-
无缝切换注意力模式:MoBA 可以在全注意力和稀疏注意力模式之间无缝切换,既保留了全注意力机制的性能,又大幅提高了计算效率。
-
少结构原则:MoBA 避免引入预定义的偏见,让模型自主决定关注点,确保了模型的灵活性和适应性。
-
高性能实现:MoBA 结合了 FlashAttention 和 MoE(混合专家模型)的优化技术,在处理 1M token 的长文本时,速度比传统全注意力机制快 6.5 倍,而在处理 10M token 时,速度提升可达 16 倍。
MoBA 已经在 Kimi 平台上得到实际验证,并且开源了相关代码,为开发者提供了便捷的集成方式。
MoBA 的主要功能
MoBA 的设计围绕以下几个核心功能展开,使其成为处理长文本任务的理想选择:
1. 块稀疏注意力
MoBA 将上下文划分为多个块(block),并让每个查询 token 动态选择最相关的键值(KV)块进行注意力计算。这种块划分策略不仅提高了计算效率,还确保了模型能够关注到最关键的信息。
2. 无参数门控机制
MoBA 引入了一种新颖的 top-k 门控机制,为每个查询 token 动态选择最相关的块。这种机制无需额外的参数训练,确保了模型的轻量化和高效性。
3. 全注意力与稀疏注意力的无缝切换
MoBA 的设计使其能够灵活地在全注意力和稀疏注意力模式之间切换,既保留了全注意力机制的性能,又大幅提高了计算效率。
4. 高性能实现
MoBA 结合了 FlashAttention 和 MoE(混合专家模型)的优化技术,显著降低了计算复杂度。实验表明,MoBA 在处理 1M token 的长文本时,速度比传统全注意力机制快 6.5 倍,而在处理 10M token 时,速度提升可达 16 倍。
5. 与现有模型的兼容性
MoBA 可以轻松集成到现有的 Transformer 模型中,无需进行大量训练调整,为开发者提供了便捷的迁移路径。
MoBA 的技术原理
MoBA 的技术原理使其在长文本处理任务中表现出色:
1. 因果性设计
为了保持自回归语言模型的因果关系,MoBA 确保查询 token 不能关注未来的块,在当前块中应用因果掩码。这种设计避免了信息泄露,同时保留了局部上下文信息。
2. 细粒度块划分与扩展性
MoBA 支持细粒度的块划分,类似于 MoE(混合专家模型)中的专家划分策略。这种设计提升了性能,使 MoBA 能够扩展到极长的上下文(如 10M token),在长上下文任务中表现出色。
MoBA 的应用场景
MoBA 的高效性和灵活性使其在多个领域具有广泛的应用潜力:
1. 长文本处理
MoBA 通过块划分和动态选择机制,显著降低了长文本处理的计算复杂度,适用于历史数据分析、复杂推理和决策等任务。
2. 长上下文语言模型
MoBA 已经被部署在 Kimi 平台上,显著提升了长上下文请求的处理效率。在处理 1M 或 10M token 的超长文本时,速度分别提升了 6.5 倍和 16 倍。
3. 多模态任务
MoBA 的架构可以扩展到多模态任务中,处理和理解多种类型的数据(如文本和图像),为复杂任务提供支持。
4. 个人助理与智能家居
在个人助理和智能家居控制中,MoBA 可以高效处理用户的长指令,通过动态注意力机制快速响应,提升用户体验。
5. 教育与学习
MoBA 可以帮助学生处理长篇学习资料,辅助完成作业,或提供基于长上下文的智能辅导。
6. 复杂推理与决策
MoBA 的动态注意力机制能够高效处理复杂的推理任务,如长链推理(CoT)和多步决策,同时保持与全注意力机制相当的性能。
MoBA 的项目地址
如果您对 MoBA 感兴趣,可以通过以下链接了解更多:
总结
MoBA 是 Moonshot AI 推出的革命性注意力机制,通过块划分和动态选择机制,显著提高了大型语言模型处理长文本的效率。其灵活的注意力模式切换、高性能实现以及与现有模型的兼容性,使其在多个领域具有广泛的应用潜力。无论是学术研究还是工业应用,MoBA 都为长文本处理任务提供了全新的解决方案。
如果您正在寻找一种高效、灵活的注意力机制,MoBA 绝对是一个值得探索的选择。


















