在人工智能领域,大型语言模型(LLM)一直是研究和应用的热点。近日,中国人民大学高瓴AI学院李崇轩、文继荣教授团队与蚂蚁集团携手,推出了全新的扩散大语言模型——LLaDA(Large Language Diffusion with mAsking)。这一模型基于扩散模型框架,而非传统的自回归模型(ARM),在文本生成、上下文学习和指令遵循等方面展现了卓越的性能。本文将深入探讨LLaDA的技术细节、功能特点及其应用场景,帮助读者全面了解这一创新模型。
什么是LLaDA?
LLaDA(Large Language Diffusion with mAsking)是一种基于扩散模型框架的大型语言模型。与传统的自回归模型不同,LLaDA采用正向掩蔽过程和反向恢复过程来建模文本分布。具体来说,模型通过逐步掩蔽文本中的标记,并在反向过程中逐步恢复这些标记,从而生成高质量的文本内容。
LLaDA的核心优势在于其非自回归生成方式。传统自回归模型在生成文本时需要逐词生成,存在顺序依赖性,容易出现“反转诅咒”问题,即在反向推理任务中表现不佳。而LLaDA通过扩散模型框架,能够同时考虑文本的双向依赖关系,从而在正向和反向推理任务中均表现出色。
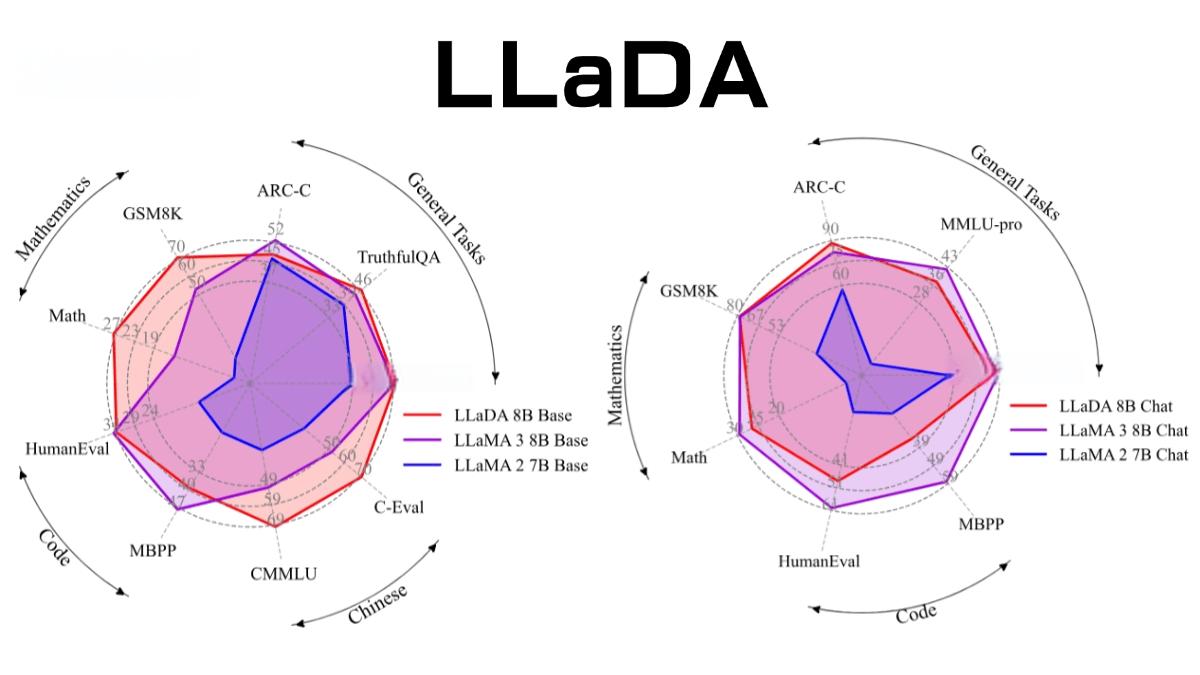
此外,LLaDA在预训练阶段使用了2.3万亿标记的海量数据,并结合监督微调(SFT)提升指令遵循能力。其8B参数版本在多项基准测试中与LLaMA3等强模型相当,展现了扩散模型作为自回归模型替代方案的巨大潜力。
LLaDA的核心功能
-
高效生成文本 LLaDA能够生成高质量、连贯的文本内容,适用于写作、对话、内容创作等多种场景。无论是生成一篇完整的文章,还是创作一段富有创意的文案,LLaDA都能轻松应对。
-
强大的上下文学习能力 LLaDA具备快速适应新任务的能力。通过分析上下文信息,模型能够迅速调整生成策略,满足不同场景的需求。
-
指令遵循能力 LLaDA在理解和执行人类指令方面表现出色,适用于多轮对话、问答和任务执行等场景。无论是简单的信息查询,还是复杂的任务执行,LLaDA都能准确理解和完成。
-
双向推理能力 传统自回归模型在反向推理任务中表现不佳,而LLaDA通过扩散模型框架解决了这一问题。在诗歌补全、数学推理等任务中,LLaDA能够实现正向和反向推理的平衡。
-
多领域适应性 LLaDA在语言理解、数学、编程、中文理解等多个领域均表现出色,具有广泛的适用性。
LLaDA的技术原理
-
扩散模型框架 LLaDA基于扩散模型框架,通过正向掩蔽过程和反向恢复过程建模文本分布。正向掩蔽过程逐步掩蔽文本中的标记,而反向恢复过程则逐步恢复这些标记,从而生成完整的文本内容。
-
掩蔽预测器 LLaDA采用普通的Transformer架构作为掩蔽预测器。输入部分掩蔽的文本序列后,模型能够预测所有掩蔽标记,从而捕捉文本的双向依赖关系。
-
优化似然下界 LLaDA通过优化似然下界进行训练,确保模型在大规模数据和模型参数下的可扩展性和生成能力。
-
预训练与监督微调 LLaDA结合了预训练和监督微调(SFT)两种方式。预训练阶段使用大规模文本数据进行无监督学习,而SFT阶段则基于标注数据提升模型的指令遵循能力。
-
灵活的采样策略 LLaDA支持多种采样策略,如随机掩蔽、低置信度掩蔽、半自回归掩蔽等,能够在生成质量和效率之间找到平衡。
LLaDA的应用场景
-
多轮对话 LLaDA能够支持流畅的多轮对话,适用于智能客服、聊天机器人等场景。无论是简单的信息查询,还是复杂的任务执行,LLaDA都能提供自然、连贯的对话体验。
-
文本生成 LLaDA在文本生成方面表现出色,适用于写作辅助、创意文案等场景。无论是生成一篇完整的文章,还是创作一段富有创意的文案,LLaDA都能轻松应对。
-
代码生成 LLaDA能够帮助开发者生成代码片段或修复错误,提升编程效率。无论是简单的代码生成,还是复杂的代码修复,LLaDA都能提供准确、高效的解决方案。
-
数学推理 LLaDA在数学推理方面表现出色,能够解决复杂的数学问题并提供解题步骤。这一功能在教育领域具有广泛的应用前景。
-
语言翻译 LLaDA支持多语言翻译,能够实现跨文化交流。无论是将中文翻译成英文,还是将英文翻译成其他语言,LLaDA都能提供高质量的翻译结果。
LLaDA的项目资源
-
GitHub仓库:https://github.com/ML-GSAI/LLaDA
-
arXiv技术论文:https://arxiv.org/pdf/2502.09992
总结
LLaDA作为中国人民大学高瓴AI学院与蚂蚁集团联合推出的扩散大语言模型,凭借其卓越的性能和广泛的应用场景,正在成为人工智能领域的一颗新星。无论是文本生成、多轮对话,还是数学推理、代码生成,LLaDA都能提供高效、准确的解决方案。随着技术的不断进步,LLaDA有望在更多领域发挥其潜力,推动人工智能技术的发展。



















