一、什么是 “可微缓存增强” 方法
“可微缓存增强” 是一种在计算机系统和算法设计中应用的技术手段。简单来说,它旨在通过优化数据的缓存管理,来显著提高系统的处理速度和资源利用效率。
二、项目介绍
“可微缓存增强”(Differentiable Cache Augmentation)采用一个经过训练的协处理器,通过潜在嵌入来增强 LLM 的键值(kv)缓存,丰富模型的内部记忆,关键在于保持基础 LLM 冻结,同时训练异步运行的协处理器。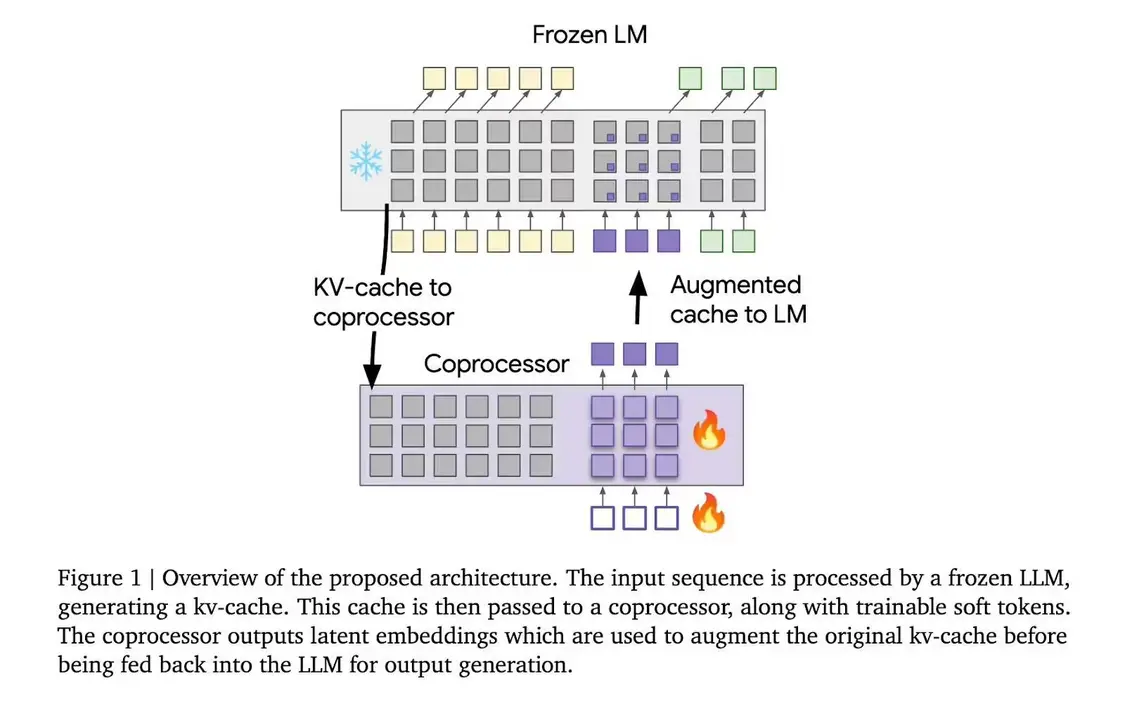
整个流程分为 3 个阶段,冻结的 LLM 从输入序列生成 kv 缓存;协处理器使用可训练软令牌处理 kv 缓存,生成潜在嵌入;增强的 kv 缓存反馈到 LLM,生成更丰富的输出。

在 Gemma-2 2B 模型上进行测试,该方法在多个基准测试中取得了显著成果。例如,在 GSM8K 数据集上,准确率提高了 10.05%;在 MMLU 上,性能提升了 4.70%。此外,该方法还降低了模型在多个标记位置的困惑度。

谷歌 DeepMind 的这项研究为增强 LLMs 的推理能力提供了新的思路。通过引入外部协处理器增强 kv 缓存,研究人员在保持计算效率的同时显著提高了模型性能,为 LLMs 处理更复杂的任务铺平了道路。
三、优势所在
-
提高性能
能够极大地减少数据访问的延迟,从而加快系统的整体运行速度。 -
适应动态变化
可以很好地应对数据访问模式的动态变化,始终保持高效的缓存利用。 -
优化资源分配
有助于更合理地分配有限的缓存空间,确保关键数据始终可快速获取。
四、应用领域
-
机器学习
在训练大规模模型时,加速数据的读取和处理。 -
数据库管理
优化数据的缓存策略,提高查询效率。 -
操作系统
提升系统对内存和缓存的管理能力。
五、未来展望
随着技术的不断发展,“可微缓存增强” 方法有望进一步完善和扩展其应用范围。它可能会与其他新兴技术相结合,为计算机系统带来更显著的性能提升。
© 版权声明
本站文章版权归奇想AI导航网所有,未经允许禁止任何形式的转载。
相关文章




















奇想AI导航网收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具,奇想AI导航网还推荐了AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。