在人工智能领域,多模态大模型正逐渐成为研究和应用的热点。HumanOmni作为一款专注于人类中心场景的多模态大模型,通过融合视觉、听觉和文本信息,为影视、教育、营销和内容创作等领域带来了全新的可能性。本文将深入解析HumanOmni的技术优势、应用场景及其在不同领域的应用潜力。
HumanOmni的技术优势
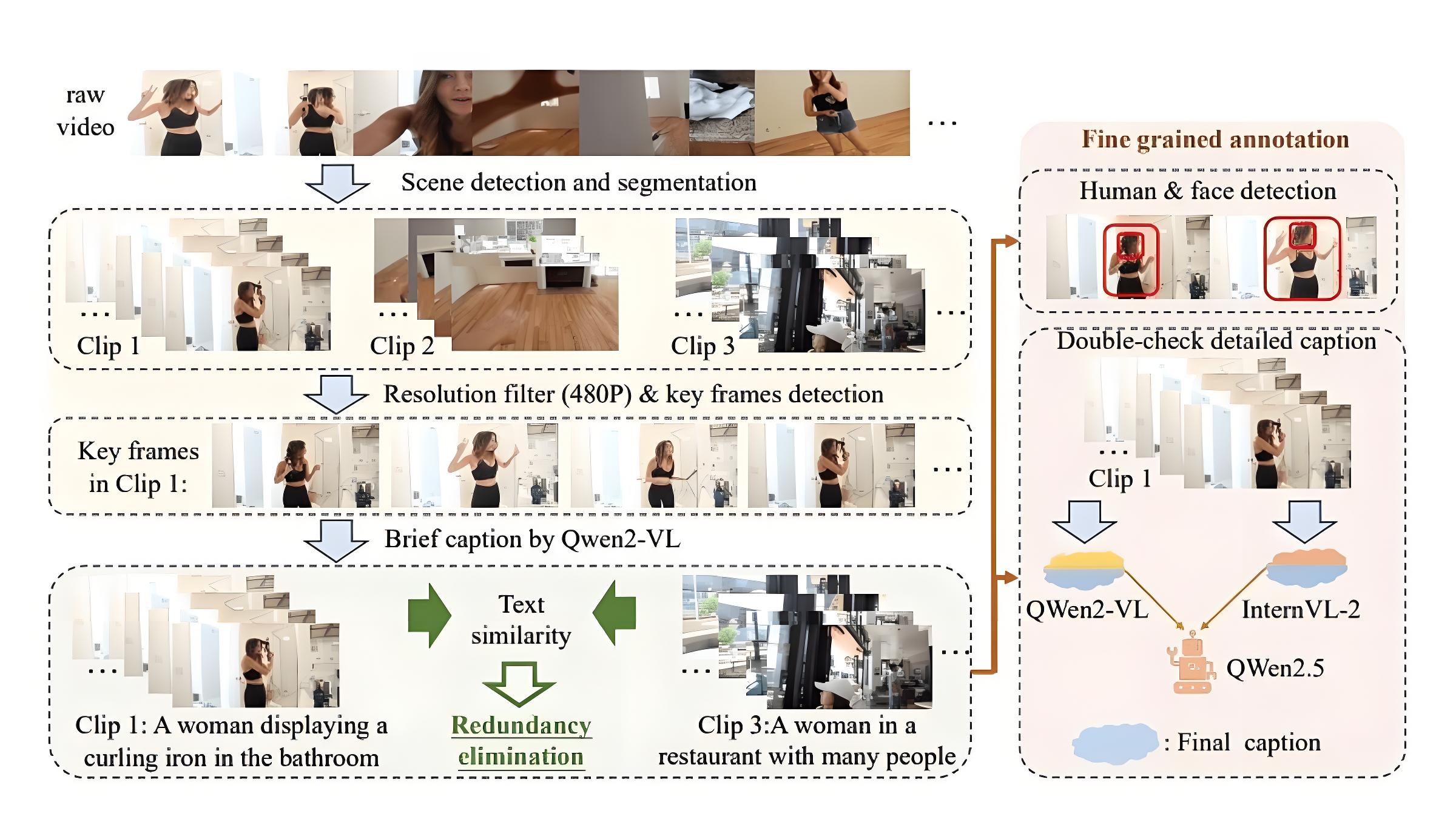
HumanOmni的核心优势在于其多模态融合架构和动态权重调整机制。通过三个专门的分支(面部相关、身体相关和交互相关),模型能够全面理解人类行为、情感和交互。动态权重调整机制使得模型能够根据不同任务需求,灵活调整各分支的权重,从而实现对复杂场景的全面理解。
多模态融合
HumanOmni能够同时处理视觉(视频)、听觉(音频)和文本信息。通过指令驱动的动态权重调整机制,模型能够将不同模态的特征进行融合,实现对复杂场景的全面理解。这种多模态融合能力使得HumanOmni在情感识别、面部描述和语音识别等方面表现出色。
技术原理
HumanOmni的技术原理包括以下几个方面:
-
多模态融合架构:通过视觉、听觉和文本三种模态的融合,实现对复杂场景的全面理解。
-
动态权重调整机制:通过BERT对用户指令进行编码,生成权重,动态调整不同分支的特征权重。
-
听觉与视觉的协同处理:使用Whisper-large-v3的音频预处理器和编码器处理音频数据,通过MLP2xGeLU将其映射到文本域。
-
多阶段训练策略:分为三个阶段,逐步构建视觉能力、发展听觉能力,并进行跨模态交互集成。
应用场景
HumanOmni的应用场景非常广泛,主要包括以下几个领域:
-
影视与娱乐:可用于虚拟角色动画生成、虚拟主播和音乐视频创作。
-
教育与培训:可以创建虚拟教师或模拟训练视频,辅助语言学习和职业技能培训。
-
广告与营销:能生成个性化广告和品牌推广视频,通过分析人物情绪和动作,提供更具吸引力的内容。
-
社交媒体与内容创作:可以帮助创作者快速生成高质量的短视频,支持互动视频创作,增加内容的趣味性和吸引力。
项目资源
HumanOmni的项目资源包括:
-
HuggingFace模型库:https://huggingface.co/StarJiaxing/HumanOmni-7B
-
arXiv技术论文:https://arxiv.org/pdf/2501.15111
总结
HumanOmni作为一款专注于人类中心场景的多模态大模型,凭借其强大的技术优势和广泛的应用场景,正在为影视、教育、营销和内容创作等领域带来全新的可能性。无论是开发者还是内容创作者,都可以通过HumanOmni实现更多创新。未来,随着技术的不断进步,HumanOmni有望在更多领域发挥其独特价值。



















